 Never Miss a Critical Alert Again
Never Miss a Critical Alert Again
How many times has a Datadog / Nagios / Zabbix alert landed in your inbox… only to be noticed hours later?
By then, the outage has escalated, the SLA is breached, and the firefighting begins. Sound familiar?
That’s exactly where Autom Mate steps in.
 Automated Escalation Alerts with Autom Mate
Automated Escalation Alerts with Autom Mate
No matter which monitoring tool you use—Nagios, Datadog, Zabbix, SolarWinds—Autom Mate can catch alerts as soon as they fire and decide what happens next.
Here’s the flow:
Incoming Alert → Autom Mate → ITSM Tool + Teams/Slack + SMS
And here’s the best part: you can handle it with predefined runbooks or let an AI Agent decide the action based on context.
 What Does Autom Mate Actually Do?
What Does Autom Mate Actually Do?
-
Receives the alert
Directly from your monitoring platform (libraries already built for Nagios, Zabbix, Datadog, SolarWinds). -
Reads the details
Full log, event text, severity. -
Decides next step
-
Runbook logic → “If Severity=Critical → Escalate”
-
Or AI agent (GPT, Claude, Llama, Copilot… you choose) → “This looks like a DB outage, escalate to DB team.”
-
-
Takes action
-
Creates ticket in ServiceNow, Jira, Ivanti, Freshservice
-
Posts rich summary into Microsoft Teams or Slack
-
Sends SMS/call via Twilio if no one responds
-
-
Keeps escalating until someone acknowledges.
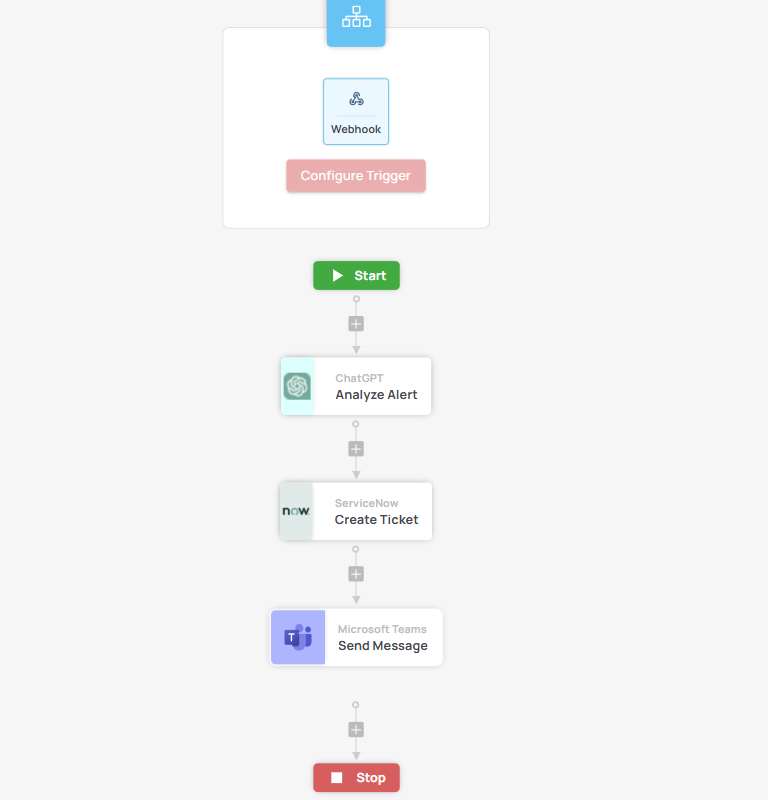
 Architecture Overview
Architecture Overview
Typical Autom Mate escalation pattern looks like this:
![]() Trigger
Trigger
Webhook from the monitoring tool when an alert is generated.
![]() Decision Layer
Decision Layer
-
Runbook condition (“Critical → Escalate”)
-
Or AI decision-making (“High CPU on prod-db01 for 15m → escalate to DB ops”)
![]() Action Layer
Action Layer
-
Create ITSM ticket in the same tool you already use
-
Post to Teams/Slack with AI summary of the raw log
-
Fire off SMS/call if no one picks it up
 AI in Action
AI in Action
Here’s how Autom Mate transforms a noisy alert:
Raw alert:
CPU usage > 95% on prod-db01 for 10+ minutes
AI-enhanced summary:
“Production database server experiencing sustained high CPU load (likely MySQL memory leak). Immediate investigation required.”
That’s the difference between “just another alert” and “clear instructions the on-call engineer can act on right now.”
 What You Gain
What You Gain
![]() Faster MTTR — alerts hit the right team immediately
Faster MTTR — alerts hit the right team immediately
![]() Zero missed escalations — Autom Mate doesn’t sleep
Zero missed escalations — Autom Mate doesn’t sleep
![]() Less noise — AI condenses logs into human language
Less noise — AI condenses logs into human language
![]() Consistent playbooks — every incident follows the same process
Consistent playbooks — every incident follows the same process
![]() ROI — less downtime, happier customers, protected SLAs
ROI — less downtime, happier customers, protected SLAs
 Try It Yourself
Try It Yourself
This use case can be built with Autom Mate’s out-of-the-box libraries:
-
Monitoring: Nagios, Zabbix, Datadog, SolarWinds
-
ITSM: ServiceNow, Jira, Ivanti, Freshservice
-
Messaging: Teams, Slack, Twilio
Start with a simple runbook → then layer in AI for smarter decisioning.
![]() Got a similar challenge?
Got a similar challenge?
How are you handling escalations today? Are you drowning in noise, or have you already started building AI-driven escalation flows?
Drop your thoughts, show us your workflows, or ask about models you can plug into Autom Mate ![]()